
 The Significance of Good Information
The Significance of Good Information
In general, almost all managers nowadays make a significant portion of their decisions based on data. Businesses are evolving at an ever-increasing speed, and competitiveness is achieved through details in opportunities and processes of innovation. Managers are fully aware that a decision based on incorrect, or out-of-context information can have a high impact on their business, and the relevance of Data Quality processes in data management is clear to any stakeholder.
The world of data has evolved exponentially in recent years in terms of technologies, architectures, and methodologies, trying to keep pace with the speed of information produced by business processes.
- In a short period, we have moved from architectures based on centralized and monolithic systems to Data Lakes and, more recently, to more distributed architectures like Data Mesh.
- Regarding reporting, a self-service architecture close to decision-makers is now unquestionable for the success of decisions.
- In terms of information management, more and more methodologies and platforms are emerging within the scope of Data Governance, which are essential for any organization to manage the information it generates and collects.
Volume of data generated, captured, copied, and consumed worldwide (in zettabytes)
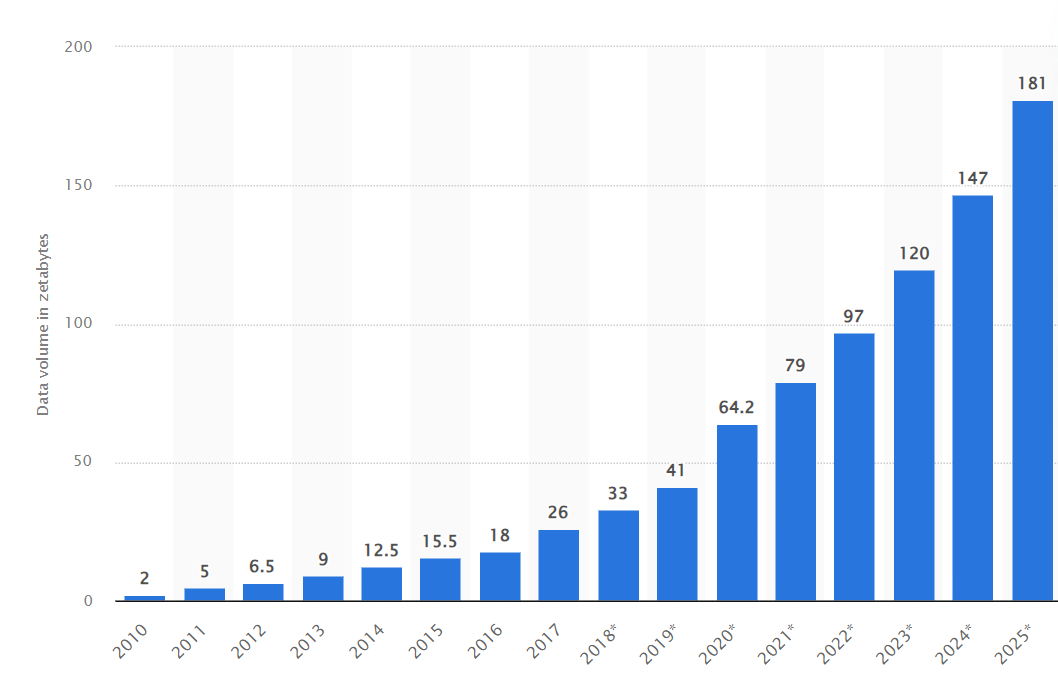
Source: statista.com
From what we know to what we do
It is in the Data Governance chapter that the component I believe is often sacrificed in information management processes lies—the Data Quality process. Despite its relevance in current information management, it is still one of the points that are often bypassed when there is a need to make decisions quickly and achieve results for the KPIs that are supporting the business processes.
For those working with data, it is not uncommon to encounter situations like these:
- The project management thinks there is low value in adding data quality-related tasks to the schedule because the initial analyses seem to reflect reality.
- The prototype dashboard based on manually collected data from operational sources, without any treatment, becomes final.
- Information is processed partially because it is poorly cataloged or lacks a person responsible for providing the correct context.
- There is replication of information in various departments because one of them cannot wait for the development team’s pipeline to add new KPIs. Replicas tend to have different information and discredit data-driven processes.
- Data normalization and treatment are not carried out, and data universes are incompatible for simultaneous analysis.
- Master data maintenance is oriented towards a report or theme, proliferating within the organization, and making reporting inconsistent between teams.
- A particular dataset has the indicators needed for a report, but what is the source of the information? At first glance, it seems correct, let’s use the dataset as a source!
What is missing for us to address and improve our approach to Data Quality?
What can we improve?
- Technology
The proliferation of data management tools is enormous, and there are more and more new tools on the market, implementing new concepts and integrated functionalities. Tools like collibra.com, opendatadiscovery.org, datadoghq.com, etc., are disruptive and allow the creation of robust governance models with a high focus on subjects such as Responsibility, Lineage and Data Observatory. They also have integrated AI functionalities that make data quality controls much more dynamic and adapted to real needs.
The adoption of these tools, prepared for a modern data stack, can be a turning point in improving the quality of information throughout an organization.
- Methodologies
While today’s technologies allow us to address the Data Quality issue in a more agile and scalable way, the non-adoption of these tools, either due to lack of resources or know-how, leaves organizations highly incapacitated in treating the quality of their data. Governance policies are fundamental to the success of any tool to be adopted. In these organizations, implementing simple methodologies/frameworks can have a high impact on the daily work with data, regardless of the tools that they use. Developing a set of simple rules widely used in all processes (Validation of referential integrity, uniqueness, null values, etc.) will make a difference in the final data quality of the entire organization. For those not willing to make these small developments, open-source technologies such as greatexpectations.io can be used.
For organizations already at a higher maturity level, it is relevant that methodologies align with the organization’s data strategy and can measure if data quality processes are effective for continuous improvement.
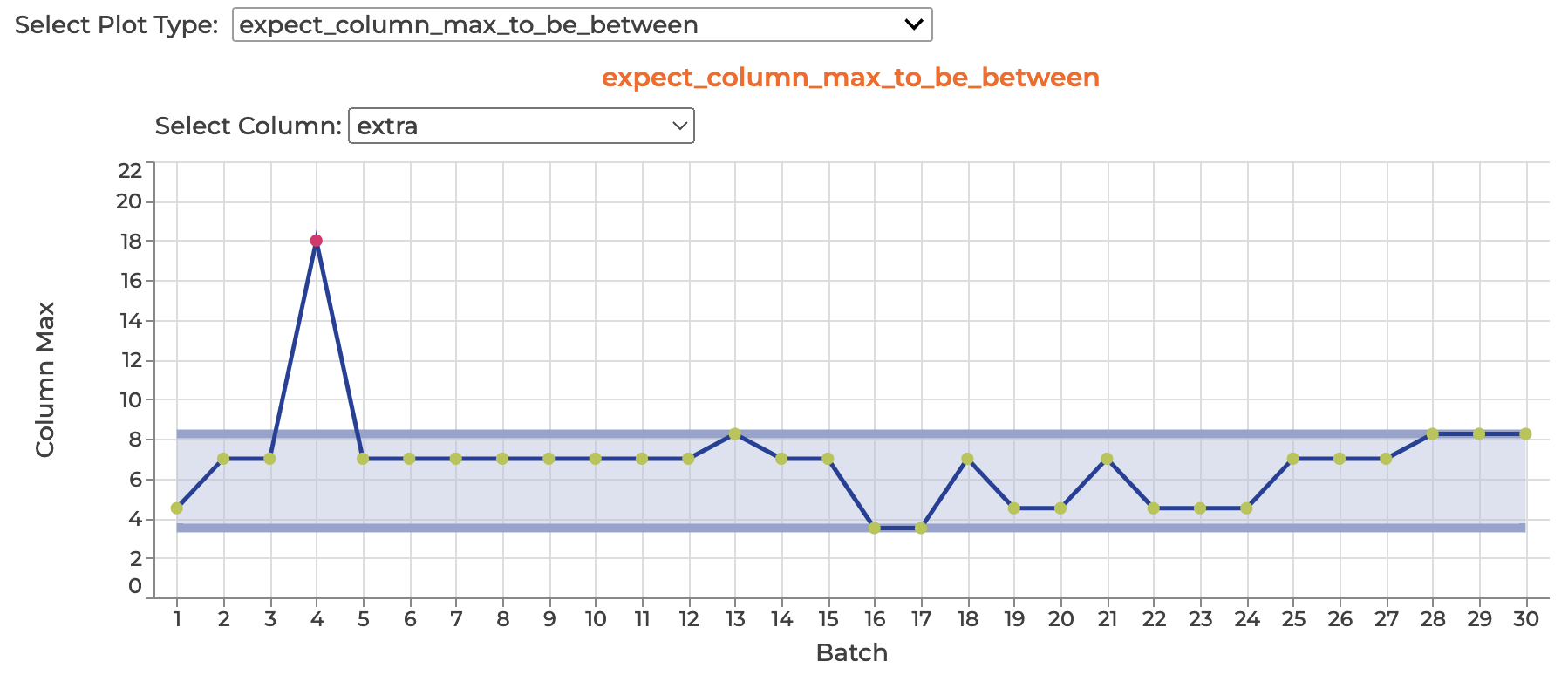
Simple rule of DQ implemented with GX (Source: https://github.com/great-expectations/great_expectations)
- Awareness
Without awareness of the relevance of Data Quality by various Data stakeholders in organizations, the adoption of new tools and methodologies has little impact. This ends up being the fundamental and driving point of this practice, and despite the talk that data is the gold of organizations, it is often not invested enough in key moments of data management. This awareness should start with voices that are most apt to speak on the subject within organizations, such as CDOs, CIOs, and Data Engineers. It should also be explored more in academia, as is already happening today with data exploration, widely taught in diverse areas of education such as Mathematics, Biology, Management, etc.
In conclusion, the journey to improve Data Quality is not just about technology—it’s a cultural shift. The voices of leaders, from CDOs to Data Engineers, must champion the importance of quality data throughout organizations.
Tiago Amoreira
Managing Partner